Milestone Project: Food Vision Big
Notebook contains the milestone project of the course TensorFlow Developer Certificate in 2022: Zero to Mastery




- Milestone Project: Food Vision Big
- Check GPU
- Get Helper functions
- Using TensorFlow Datasets
- Exploring the Food 10 data from TensorFlow Datasets
- Plot an image from TensorFlow Datasets
- Preprocessing our data
- Batch & Prepare datasets
- Create modelling callbacks
- Setup Mixed precision training
- Build feature extraction model
- Checking layes datatype policies(verifying mixed precision)
- Fit the feature extraction Model
- Milestone Project 1: FOODVISION model
Milestone Project: Food Vision Big
This Notebook is an account of my working for the Udemy course :TensorFlow Developer Certificate in 2022: Zero to Mastery. This Notebook covers:
- Using TensorFlow Datasets to download and explore data(all of Food101)
- Creating a preprocessing function for our data
- Batching and preparing datasets for modelling(making them run fast)
- Setting up mixed precision training(faster model training)
As a part of the project:
- Building and training a feature extraction model
- Fine-tuning feature extraction model to beat the DeepFoodpaper
- Evaluating model results on TensorBoard
- Evaluating model results by making and plotting predictions.
Check GPU
- Google colab offers GPUs, however not all of them are compatible with mixed prcision training.
Google Colab offers:
- K80 (not compatible)
- P100 (not compatible)
- Tesla T4 (compatible)
Knowing this, in order to use mixed precision training we need access to a Tesla T4 (from within goole colab) or if we're using our own hardware our GPU needs a score of 7.0+
# re-running this cell
!nvidia-smi -L
!wget https://raw.githubusercontent.com/mrdbourke/tensorflow-deep-learning/main/extras/helper_functions.py
from helper_functions import create_tensorboard_callback, plot_loss_curves, compare_historys
Using TensorFlow Datasets
TensorFlow Datasets is a place for prepared and ready-to-use machine learning datasets. Using TensorFlow datasets we can download some famous datasets to work on via the API.
Why use TensorFlow Datasets?
- Load data already in Tensor format
- Practice on well established datasets(for many different problem types)
- Experiment with different modelling techniques on a consisten dataset.
Why not use TensorFlow Datasets?
- Datasets are static (do not change like real-world datasets)
import tensorflow_datasets as tfds
datasets_list = tfds.list_builders()# Get all available datasets in TFDS
print("food101" in datasets_list) # is our target dataset in the list of TFDS datasets
(train_data, test_data), ds_info = tfds.load(name = "food101",
split = ["train", "validation"],
shuffle_files = True,
as_supervised = True, # data returned in tuple format(data,label)
with_info = True)
ds_info.features
classnames = ds_info.features["label"].names
classnames[:10]
train_one_sample = train_data.take(1) # sampls are in format (image_tensor, label)
train_one_sample
for image, label in train_one_sample:
print(f"""
Image shape; {image.shape},
Image datatype : {image.dtype},
Target class from Food 101 (tensor form): {label},
Class name (str form): {classnames[label.numpy()]}
""")
# What does our image tensor look like from TFDS's Food101 look like?
image
import tensorflow as tf
tf.reduce_min(image), tf.reduce_max(image)
import matplotlib.pyplot as plt
plt.style.use('dark_background')
plt.imshow(image)
plt.title(classnames[label.numpy()]) # Add title to image to verify
plt.axis(False)

Preprocessing our data
Neural Networks performs the best when data is in a certain way (e.g. batched, normalized etc.)
So in order to get it ready for a neural network, you'll often have to write preprocessing functions and map it to your data.
What we know about our data:
- In
uint8datatype. - Comprise of all different size tensors(different sized images)
- Not scaled (the pixel values are between 0 & 255 )
What we know models like:
- Data in
float32dtype (or for mixed precisionfloat16andfloat32) - For batches tensorflow likes all of the tensors within a batch to be of same size
- Scaled (values between 0 &1 ) also called normalized tensors generally perform better.
Since, we're going to be using an EfficientNetBX pretrained model from tf.keras.applications we don't need to rescale our data(these architectures have rescaling built-in)
This means our functions need to:
- Reshape our images to all the same size
- Conver the dtype of our image tensors from
uint8tofloat32
def preprocess_img(image, label, img_shape = 224):
"""
Converts image datatype from 'uint8' -> 'float32' and reshapes
image to [img_shape, img_shape, colour_channels]
"""
image = tf.image.resize(image, [img_shape, img_shape] ) # Reshape target image
#image = image/255. # Scaling images (not required for EfficientNetBX models)
return tf.cast(image, tf.float32), label # returns (float32_image, label) tuple
# Preprocess a single sample of image and check the outputs
preprocessed_img = preprocess_img(image, label)[0]
print(f"Image before preprocessing :\n {image[:2]}..., \n Shape: {image.shape}, \n Datatype:{image.dtype}")
print(f"Image after preprocessing :\n {preprocessed_img[:2]}..., \n Shape: {preprocessed_img.shape} , \n Datatype:{preprocessed_img.dtype}")
# Map preprocessing function to training data ( and parallelize it)
train_data = train_data.map(map_func = preprocess_img, num_parallel_calls = tf.data.AUTOTUNE)
# Shuffle train data and turn it into data and prefetch it (load it faster)
train_data = train_data.shuffle(buffer_size = 1000).batch(batch_size = 32).prefetch(buffer_size = tf.data.AUTOTUNE)
# Map preprocessing function to test data
#test_data = test_data.map(map_func = preprocess_img, num_parallel_class= tf.data.AUTOTUNE)
test_data = test_data.shuffle(buffer_size = 1000).batch(batch_size=32).prefetch(buffer_size = tf.data.AUTOTUNE)
train_data, test_data
Tensorflow maps this preprocessing function(
preprocess_img) across our training dataset, then shuffle a number of elements and then batch them together and finally make sure you prepare new batches(prefetch) whilst the model is looking through (finding patterns) in the current batch.
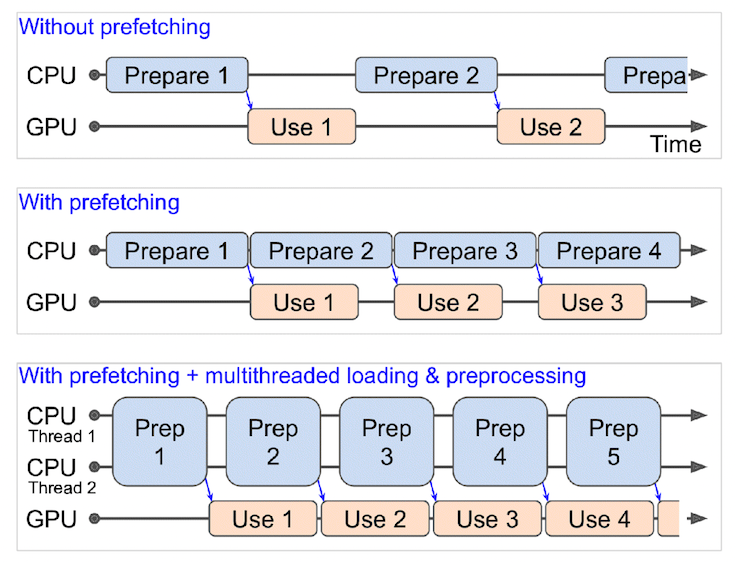 What happens when you use prefetching (faster) versus what happens when you don't use prefetching (slower). Source: Page 422 of Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow Book by Aurélien Géron.
What happens when you use prefetching (faster) versus what happens when you don't use prefetching (slower). Source: Page 422 of Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow Book by Aurélien Géron.
from helper_functions import create_tensorboard_callback
# Create a Modelcheckpoint callback to save a model's progress during training
checkpoint_path= "model_checkpoints/cp.ckpt"
model_checkpoint = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,
monitor = "val_acc",
save_best_only = True,
save_weights_only = True,
verbose = 0) # Dont print whether or not model is being saved
Setup Mixed precision training
For Deep understanding of mixed precision training, check out the TensorFlow guide: https://www.tensorflow.org/guide/mixed_precision
Mixed precision utilizes a combination of float32 and float16 datatypes to speed up model performance
from tensorflow.keras import mixed_precision
mixed_precision.set_global_policy("mixed_float16") # set global data policy to mixed precision
!nvidia-smi
mixed_precision.global_policy()
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
# Create a base model
input_shape = (224,224,3)
base_model = tf.keras.applications.EfficientNetB0(include_top=False)
base_model.trainable = False
# Create a functional model
inputs = layers.Input(shape = input_shape, name = "input_layer")
# Note: EfficientNetBX models have rescaling built-in but if your model doesn't you need to have
# x = preprocessing.Rescaling(1/255.)(x)
x = base_model(inputs, training = False)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(len(classnames))(x)
outputs = layers.Activation("softmax", dtype = tf.float32, name = "softmax_float32")(x)
model = tf.keras.Model(inputs,outputs)
# Compile the model
model.compile(loss = "sparse_categorical_crossentropy",
optimizer = tf.keras.optimizers.Adam(),
metrics = ["accuracy"])
model.summary()
for layer in model.layers:
print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
Going through the above output we notice:
-
layer.name: the human readable name of a particular layer -
layer.trainable: is the layer trainable or not? -
layer.dtype: the data type of layer stores its variables in -
layer.dtype_policy: the data type policy a layers computes on its variables with
# Check the base model layers dtypes
for layer in model.layers[1].layers:
print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
# Fit the model with callbacks
history_101_food_classes_feature_extract = model.fit(train_data,
epochs=3,
steps_per_epoch=len(train_data),
validation_data=test_data,
validation_steps=int(0.15 * len(test_data)),
callbacks=[create_tensorboard_callback("training_logs",
"efficientnetb0_101_classes_all_data_feature_extract"),
model_checkpoint])
Nice, looks like our feature extraction model is performing pretty well. How about we evaluate it on the whole test dataset?
results_feature_extract_model = model.evaluate(test_data)
results_feature_extract_model
!mkdir -p saved_model
loaded_model = tf.keras.models.load_model('saved_model/food_vision_big')
# Check the layers in the base model and see what dtype policy they're using
for layer in base_model.layers:
print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
results_loaded_model = loaded_model.evaluate(test_data)
# Note: this will only work if you've instatiated results variables
import numpy as np
assert np.isclose(results_feature_extract_model, results_loaded_model).all()
TODO: Preparing our model's layers for fine-tuning
Next: Fine-tune the feature extraction model to beat the DeepFood paper.
Like all good cooking shows, I've saved a model I prepared earlier (the feature extraction model from above) to Google Storage.
You can download it to make sure you're using the same model as originall trained going forward.
!wget https://storage.googleapis.com/ztm_tf_course/food_vision/07_efficientnetb0_feature_extract_model_mixed_precision.zip
!mkdir downloaded_gs_model # create new dir to store downloaded feature extraction model
!unzip 07_efficientnetb0_feature_extract_model_mixed_precision.zip -d downloaded_gs_model
# Load and evaluate downloaded GS model
tf.get_logger().setLevel('INFO') # hide warning logs
loaded_gs_model = tf.keras.models.load_model("downloaded_gs_model/07_efficientnetb0_feature_extract_model_mixed_precision")
loaded_gs_model.summary()
results_loaded_gs_model = loaded_gs_model.evaluate(test_data)
results_loaded_gs_model
for layer in loaded_gs_model.layers:
layer.trainable = True # set all layers to trainable
print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
for layer in loaded_gs_model.layers:
print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
So, Now we have all our layers trainable. We are going to train our model on the dataset with all the layers unfrozen and try to beat the results of DeepFood Paper (which has accuracy close to 77%)
# Monitor the val_loss and stop training if it doesn't improve for 3 epochs
EarlyStopping_callback = tf.keras.callbacks.EarlyStopping(monitor = "val_loss",
patience = 3, verbose = 0)
# Create ModelCheckpoint callback to save best model during fine-tuning
# Save the best model only
# Monitor val_loss while training and save the best model (lowest val_loss)
checkpoint_path = "fine_tune_checkpoints/"
model_checkpoint = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,
save_best_only=True,
monitor="val_loss")
# Creating learning rate reduction callback
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor="val_loss",
factor=0.2, # multiply the learning rate by 0.2 (reduce by 5x)
patience=2,
verbose=1, # print out when learning rate goes down
min_lr=1e-7)
# Use the Adam optimizer with a 10x lower than default learning rate
loaded_gs_model.compile(loss = "sparse_categorical_crossentropy",
optimizer = tf.keras.optimizers.Adam(),
metrics = ["accuracy"])
# Use 100 epochs as the default
# Validate on 15% of the test_data
# Use the create_tensorboard_callback, ModelCheckpoint and EarlyStopping callbacks you created eaelier
history_101_food_classes_all_data_fine_tune = loaded_gs_model.fit(train_data,
epochs = 100,
steps_per_epoch = len(train_data),
validation_data = test_data,
validation_steps = int(0.15*len(test_data)),
callbacks = [create_tensorboard_callback("training_logs", "efficientb0_101_classes_all_data_fine_tuning"),
model_checkpoint,
EarlyStopping_callback,
reduce_lr])
!tensorboard dev upload --logdir ./training_logs \
--name "Fine-tuning EfficientNetB0 on all Food101 Data" \
--description "Training results for fine-tuning EfficientNetB0 on Food101 Data with learning rate 0.0001" \
TODO: Evaluate your trained model
Some ideas you might want to go through:
- Find the precision, recall and f1 scores for each class (all 101).
- Build a confusion matrix for each of the classes.
- Find your model's most wrong predictions (those with the highest prediction probability but the wrong prediction).
pred_probs = loaded_gs_model.predict(test_data, verbose=1) # set verbosity to see how long it will take
len(pred_probs)
pred_probs.shape
# How do they look?
pred_probs[:10]
print(f"Number of prediction probabilities for sample 0: {len(pred_probs[0])}")
print(f"What prediction probability sample 0 looks like:\n {pred_probs[0]}")
print(f"The class with the highest predicted probability by the model for sample 0: {pred_probs[0].argmax()}")
pred_classes = pred_probs.argmax(axis=1)
# How do they look?
pred_classes.shape
y_labels = []
for images, labels in test_data.unbatch(): # unbatch the test data and get images and labels
y_labels.append(labels.numpy().argmax()) # append the index which has the largest value (labels are one-hot)
y_labels[:10] # check what they look like (unshuffled)
len(y_labels)
from sklearn.metrics import accuracy_score
sklearn_accuracy = accuracy_score(y_labels, pred_classes)
sklearn_accuracy
(train_data, test_data), ds_info = tfds.load(name="food101", # target dataset to get from TFDS
split=["train", "validation"], # what splits of data should we get? note: not all datasets have train, valid, test
shuffle_files=True, # shuffle files on download?
as_supervised=True, # download data in tuple format (sample, label), e.g. (image, label)
with_info=True) # include dataset metadata? if so, tfds.load() returns tuple (data, ds_info)
class_names = ds_info.features["label"].names
class_names[:10]